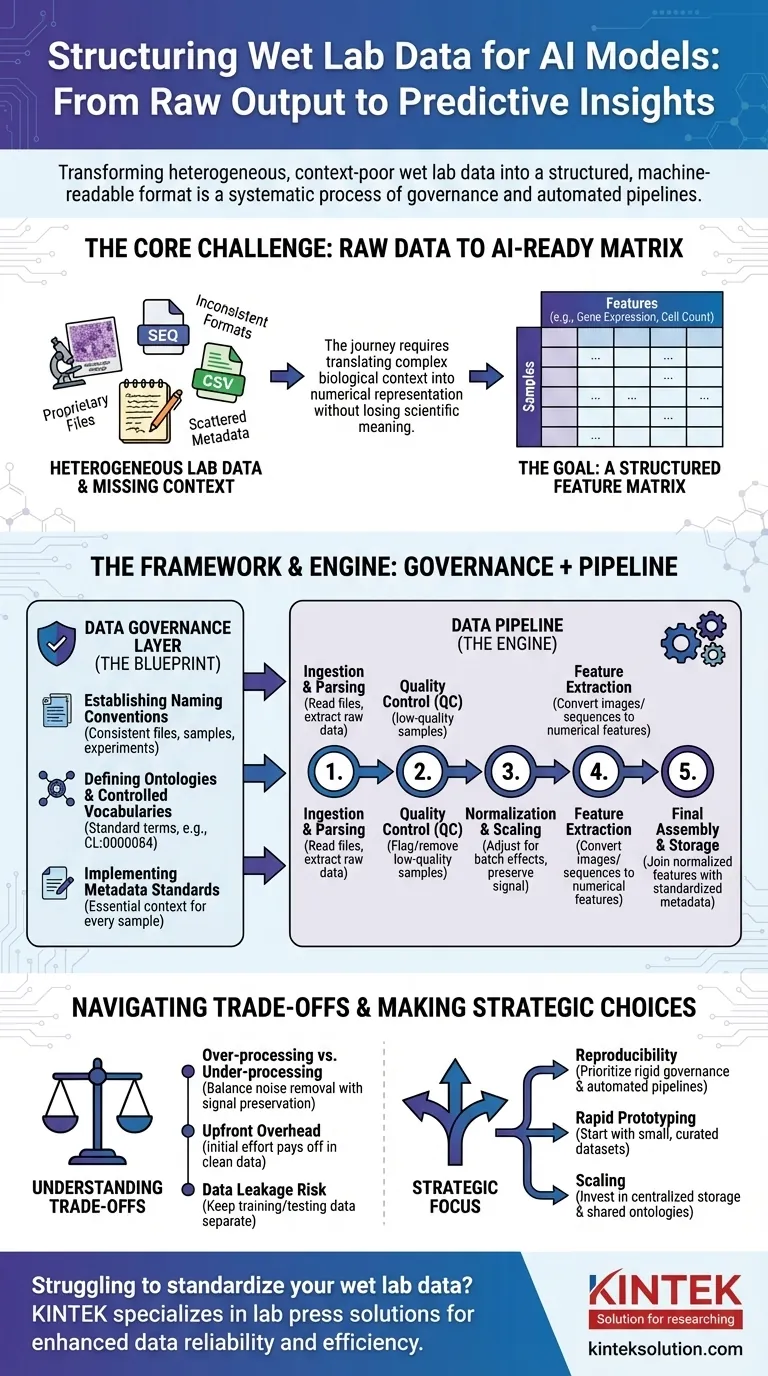
为了准备用于AI的湿实验室数据,您必须将其从原始的、通常不一致的状态转换为结构化的、机器可读的格式。这不是一个单一的步骤,而是一个系统的过程,它涉及数据治理以创建明确的规则,然后通过数据管道自动化地对原始实验输出进行清理、规范化和结构化,使其成为适合模型训练的一致格式。
核心挑战不仅仅是重新格式化文件。它是关于系统地将复杂的生物学背景(如实验条件、样本历史和测量技术)转换为结构化的数值表示,以便AI模型能够从中学习而不会丢失关键的科学意义。
核心问题:从原始输出到AI可用数据
从实验室工作台到预测模型的旅程充满了数据挑战。科学仪器的原始输出很少(甚至从未)可以直接用于AI算法。
实验室数据的异构性
湿实验室数据以各种各样的格式存在。这包括从测序仪和显微镜的专有文件到来自酶标仪的简单CSV文件,每种文件都有自己的结构和特点。
然而,AI模型需要统一的格式。
缺失上下文的困扰
关键信息,即元数据,通常分散在各处。它可能在科学家的笔记本中、单独的电子表格中,或者仅仅存在于他们的头脑中。没有这些上下文(例如,使用了哪种药物,温度,所用的细胞系),数值数据将毫无意义。
目标:特征矩阵
最终,大多数AI模型需要特征矩阵形式的数据。这是一个简单的表格,其中行代表单个样本(例如,患者、细胞培养孔),列代表特征(例如,基因表达水平、细胞形态测量、蛋白质浓度)。

标准化框架:数据治理层
在构建自动化管道之前,您必须建立规则。这就是数据治理——确保所有实验和团队之间一致性的蓝图。这是最关键也最常被忽视的步骤。
建立命名约定
一个简单但强大的规则是强制执行文件、样本和实验的一致命名方案。这使得数据能够从其来源到最终分析进行程序化链接和跟踪。
定义本体和受控词汇
本体为描述生物实体提供了一套标准术语。例如,与其允许“T-cell”、“T lymphocyte”和“Tcell”,受控词汇会强制使用一个单一术语,如来自细胞本体论的CL:0000084。
这可以防止歧义,并确保来自不同实验的数据真正可比较。
实施元数据标准
您必须定义每个样本必须捕获的最小元数据。这通常包括样本来源、实验条件、仪器设置和日期。此规则确保没有数据点成为孤儿,脱离其上下文。
转换引擎:构建数据管道
有了治理规则,您就可以构建数据管道。这是一系列自动化软件步骤,将原始数据转换为最终的AI就绪特征矩阵。
步骤1:数据摄取和解析
管道的首要任务是查找并读取原始数据文件。此步骤涉及为每种仪器的输出格式编写特定的解析器,以提取主要测量结果和任何相关的元数据。
步骤2:质量控制(QC)
并非所有数据都是好数据。管道应根据预定义指标自动标记或删除低质量样本,例如成像实验中细胞计数低或测序仪读数质量差。
步骤3:标准化和缩放
不同批次或板的测量结果通常存在技术差异。标准化是一个关键步骤,它调整数据以使测量结果在不同实验之间具有可比性,在保留生物学信号的同时去除技术噪声。
步骤4:特征提取
原始数据通常不是特征格式。例如,图像必须经过处理才能提取诸如细胞大小、形状和强度等数值特征。DNA序列可以转换为k-mer频率向量。此步骤将复杂数据转换为AI可以使用的数字。
步骤5:最终组装和存储
最后,管道将标准化特征与标准化元数据结合起来。这创建了最终的、干净的特征矩阵,然后将其保存为稳定、可查询的格式(如Parquet或数据库)用于模型训练。
了解权衡
数据结构化不是一个中立的过程。您做出的每一个选择都可能影响最终模型的性能和解释。
过度处理与处理不足
激进的标准化或过滤有时会消除细微但重要的生物学信号。相反,未能消除技术噪声将确保您的模型从实验伪影而非生物学中学习。这是一个持续的平衡。
标准化会产生前期开销
实施数据治理需要大量的前期努力和整个团队的认同。它最初可能会感觉减缓了研究速度,但通过避免数月的后期清理工作,它会带来巨大的回报。
数据泄露的危险
一个关键的管道功能是保持训练数据和测试数据分离。如果测试集的信息(例如其整体分布)被用于标准化训练集,您的模型性能将被人为夸大,并且在实际应用中会失败。
根据您的目标做出正确选择
您处理数据结构的方法应以您的最终目标为指导。
- 如果您的主要关注点是可重现性:优先考虑严格的数据治理和从一开始就进行版本控制、完全自动化的管道。
- 如果您的主要关注点是快速原型设计:从小规模、手动整理的数据集开始,以验证您的AI方法,然后再投资于全面的管道。
- 如果您的主要关注点是在大型组织中进行扩展:大力投资于集中式数据存储、共享本体和通用管道组件,以防止数据孤岛。
最终,以对待湿实验室实验同样的严谨性对待您的数据,是构建成功可靠的生物AI的基础。
总结表:
| 步骤 | 关键行动 | 目的 |
|---|---|---|
| 数据治理 | 建立命名约定、本体、元数据标准 | 确保实验之间的一致性和可比性 |
| 数据管道 | 摄取、解析、质量控制、标准化、提取特征、组装 | 自动化将原始数据转换为AI就绪特征矩阵的过程 |
| 权衡 | 平衡过度处理与处理不足,管理开销 | 优化模型性能并避免数据泄露 |
还在为AI湿实验室数据标准化而烦恼吗?KINTEK专注于实验室压片机,包括自动实验室压片机、等静压机和加热压片机,为实验室提供服务以提高数据可靠性和实验效率。让我们帮助您获得一致的结果——立即联系我们讨论您的需求,发现我们的解决方案如何支持您的AI驱动研究!
图解指南